Inspecting SHA256 internal variables
This is just for fun. I was curious about the Bitcoin system and that lead me to take a look at SHA256 to see how the digest is built. After some reading, I ended up with some questions so I coded a little app to help me visualize what happens during the process. I know Google could answer it quickly, but I wanted to check it by myself :).The questions and findings are below.
App & Source Code
(SHA256 of the file is 9ea7aad9ac884c5a8a3e9459b7efe8fe4a9b09c7b998f8da6c821ecdc42d3e98).
References
There are lots of sources about the subject. I used the following ones as references:Questions & Comments
SHA256 uses two blocks of constants to fill the initial values for the HASH and the variables for the compression of the message block (the Message block has 512 bits, and the resulting Hash is 256 bits). For the initialization of the hash: "These words were obtained by taking the first thirty-two two bits of the fractional parts of the square roots of the first eight prime numbers". The variables used for the compression function have a similar origin: "These words represent the first thirty-two bits of the fractional parts of the cube roots of the first sixty-four prime numbers."
Mistery solved. Interesting to note that this info is often supressed from the available (free) code, you see just a bunch of numbers without any explanations.
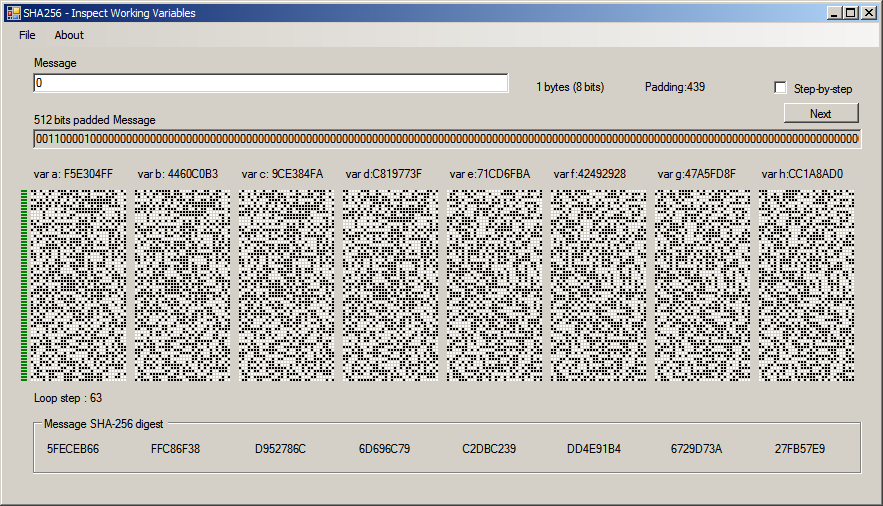
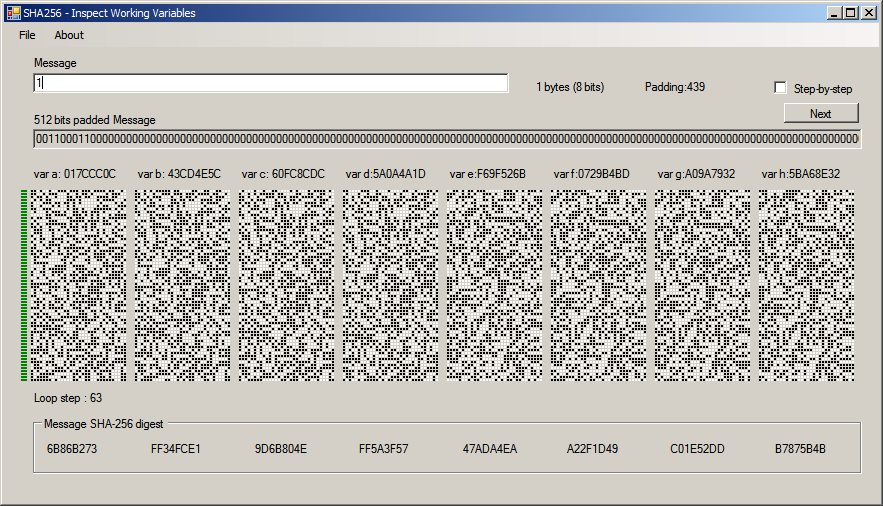
Answer: A LOT! Changing a single input bit causes a huge change on almost every stage of the processing loop. It can be seen below: the first image is the processing of a single byte message "0" (binary 00110000). The second is the the processing of "1" (00110001). Just compare both to see that after some steps any similarity is gone.
This is mainly due to the transformations, additions and variable swapping that occurs at every cycle. To make things more interesting, after the 15th cycle, the output also participates on the input for the next cycle.
In theory, yes. Pratically, it seems that the answer is no (with actual processing power). Dang describes 3 security characteristics of the SHA algorithms (Collision resistence, Preimage resistance and Second Preimage resistance). The interesting one (in my opinion) is Collision, which in simple terms means "how to find a message Y with the same hash value as a message X".
I believe this is a valid example: A bank sends a document to an agency saying "Don't give msarmento any money", and publish it with a hash XXXXX. A possible collision attack will try to find a way to alter the original document (something like "Give msarmento 1 million dollars!") in a way that the resulting hash will be the same as the original one.
As a curiosity, there is an study about Bitcoin processing that explain a little about the difficulties to find possible shortcuts and/or optimizations for finding SHA keys. Despite the fact that the study is oriented for a very specific case (Bitcoin), it helps to understand why is so hard to break the SHA algorithms. Here's the link for the Courtois/Grajek/Naik document (The Unreasonable Fundamentals Incertitudes Behind Bitcoin Mining).